Three Text Classification Techniques That Require Little to no Data

This article will discuss potential text classification techniques you can use for your next NLP project that require little to no training cases and only a small amount of code. All three techniques leverage Transformer models, which are becoming increasingly capable at performing text classification. It's important that you're familiar with the three techniques, as one of them could save you an amount of immense time for your next text classification project.
Zero-Shot NLI Model
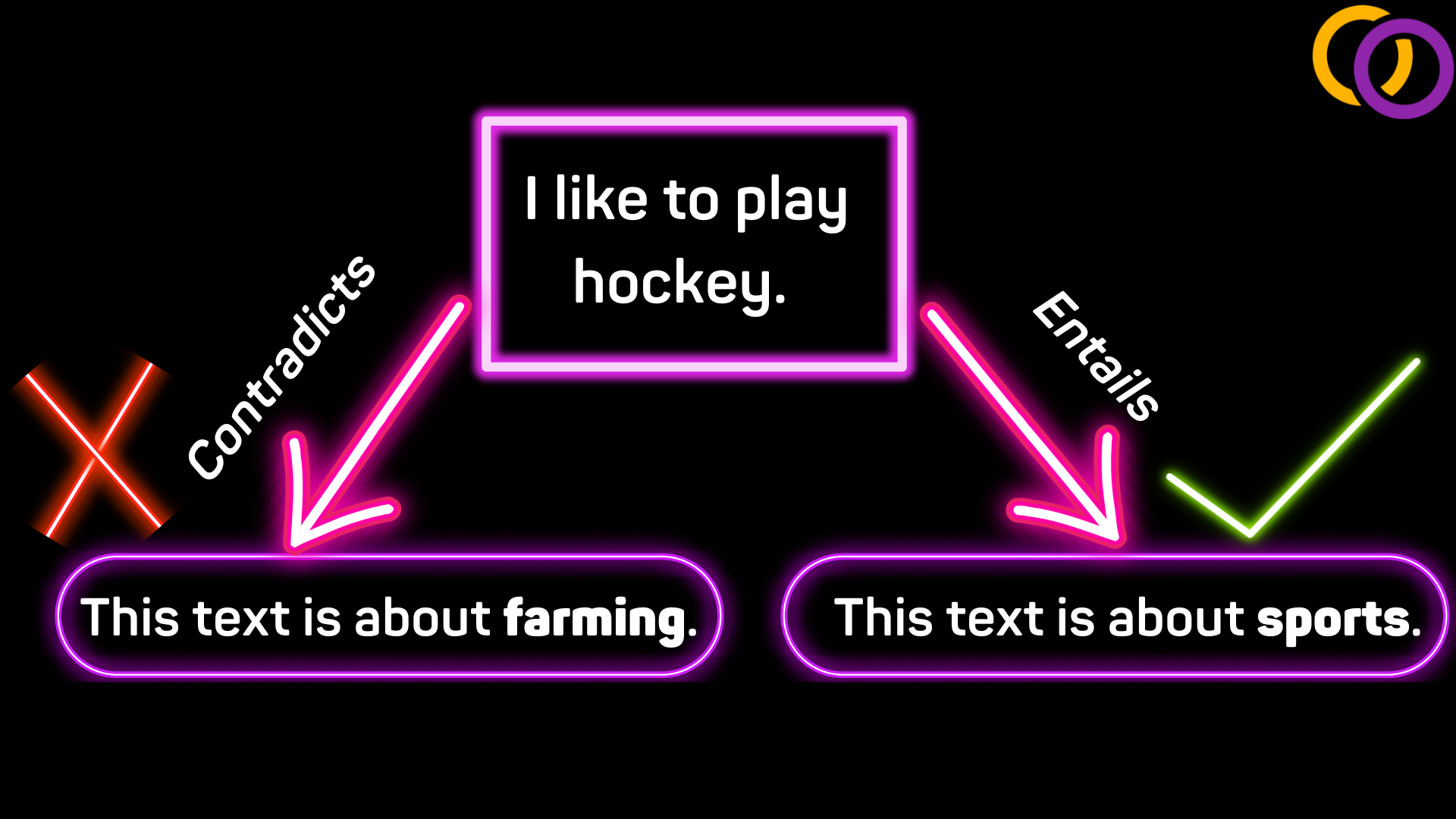
We can use a model trained for natural language inference (NLI) to classify text into arbitrary categories without the need for any training data. NLI involves determining if an input contradicts, is neutral to, or entails another input. Researchers from the University of Pennsylvania proposed a technique to adapt an NLI model to perform text classification by reformulating the input to the model.
Figure 1 demonstrates an NLI model performing text classification. Given the text "I like to play hockey," which we wish to classify, and the labels "farming" and "sports," we produced the two hypotheses that followed the pattern "this text is about X" where X is one of the labels. The model would, in theory, be able to detect that the hypothesis with the label "sports" entails the text while the other hypothesis contradicts the text, and thus the "sports" label is chosen.
Hugging Face has created abstractions to allow us to use a zero-shot NLI text classification model with just a few lines of code through their Transformers library. We'll start by pip installing the Transformers library.
pip install transformersNow we can import a class called pipeline which we’ll use to install the model.
from transformers import pipelineTo load a model with the Pipeline class we need two inputs, the task we’re performing and the model name. The task name is “zero-shot-text-classification” and the the model name can be found on Hugging Face’s Model Hub and is “facebook/bart-large-mnli” – the most downloaded zero-shot text classification model on the Hub.
task = "zero-shot-classification"
model = "facebook/bart-large-mnli"
classifier = pipeline(task, model)We'll provide inputs that you may expect for a sentiment analysis problem.
labels = ["negative", "positive"]
text = "I loved the movie so much."We can now classify text by calling our classifier and providing the text we want to classify to the first position parameter and the labels to the second. The output is a dictionary that contains the results.
result = classifier(text, labels)
print(result)Result:
{'sequence': 'I loved the movie so much.', 'labels': ['positive', 'negative'], 'scores': [0.9705924391746521, 0.02940751425921917]}
The dictionary contains three keys: sentences, scores, and labels. The "labels" key contains a list in order of which labels had the highest scores. Similarly, the scores key contains a list of the scores in order of highest to lowest, where each score is within the range of 0-1 with higher scores being better. The code below isolates the top label and score for the case.
print(result["labels"][0])
print(result["scores"][0])Result:
positive
0.9705924391746521
Few-Shot Learning with a Text Generation Model
Prompt engineering is a new technique that is becoming increasingly popular within the field of NLP. It works by leveraging large pre-trained text generation models, like GPT-3, to produce text to solve a problem that has been provided within the text input. The models continue the prompt one token at a time and, by doing so, it solves the task posed within the prompt.
Prompt engineering can be applied to enable a text generation model to perform text classification. The prompt will contain a few training cases, and thus, the technique is considered a "few-shot" approach. For this tutorial, we'll use a fully open-sourced version of GPT-3 called GPT-Neo by Eleuther AI to perform text classification. We'll implement it with my very own Python Package called Happy Transformer that abstracts Hugging Face's Transformers library.
Let's install Happy Transformer.
pip install happytransformerNow, we'll import a class called HappyGeneration which we'll use to load the model, and a Dataclass called GENSettings for storing the settings we'll use for inference.
from happytransformer import HappyGeneration, GENSettingsThere are several GPT-Neo models we can use, ranging from 125M parameters to 20B parameters. In general, you can expect the larger models to perform better but require more VRAM and take longer to run. We'll use the largest model a high ram Google Colab instance can handle, which has 1.3B parameters.
We'll load the model using HappyGeneration and provide the model type ("GPT-NEO") to the first position parameter and the model name to the second.
happy_gen = HappyGeneration("GPT-NEO", "EleutherAI/gpt-neo-1.3B")We need to use a prompt that contains a few cases for the task we wish to perform and then a case that follows the same format as the provided cases but without the answer present.
prompt = """Review: 'I loved the movie.'
Sentiment: Positive
####
Review: 'Horrible acting and a boring script. "
Sentiment: Negative
####
Review: 'I wish the movie never ended I was enjoying it so much. I can't wait for the sequel."
Sentiment: Positive
####
Review: 'Two thumbs down. I almost turned it off midway through.'
Sentiment: Negative
####
Review: 'Great acting and writing. I will for sure watch it again.'
Sentiment:""" So when we provide this prompt to the model, it will attempt to determine if the sentiment for the text "Great acting and writing..." is "Positive" or "Negative" by continuing the prompt.
We'll also define the inference settings we'll use. We only require the first token that will be outputted so we can set both the min length and max length parameter to 1.
args = GENSettings(min_length=1, max_length=1)We're now ready to classify text. We'll provide the prompt and the args variables to happy_gen's generate_text method.
result= happy_gen.generate_text(prompt, args=args)
print(result)Result:
GenerationResult(text=' Positive')
The result is a Dataclass object with a single variable called text. We can isolate the prediction with the code below. We can also remove any whitespace the model may have added by calling strip().
print(result.text.strip())Result:
Positive
Already Fine-Tuned Transformer Model
The most common way to use Transformer models to classify text is to fine-tune a pre-trained model like BERT. The process of fine-tuning a model for text classification is easy given enough data and Happy Transformer (see this tutorial). But, you may not have any data at all to train the model. So, in this case, I suggest you search on Hugging Face's Model Hub to see if someone has uploaded a model to accomplish your task. You can see available text classification models on the Hub by going to this webpage. You can also use their various search tools to help locate a model that suits your need. In this article, we'll use a model called model that was trained to detect six types of emotions called "bhadresh-savani/distilbert-base-uncased-emotion."
Since Happy Transformer has already been installed from the previous section, we can move on to importing the class we'll use to download the model called HappyTextToText.
From happytransformer import HappyTextClassificationLet's insatiate a model. We'll provide the model type and name to the first two position parameters. For the named parameter called "num_labels" we'll provide the number of possible classes the model will classify the text into, which in this case is 6: sadness, joy, love, anger, fear and surprise.
happy_tc = HappyTextClassification("DISTILBERT", "bhadresh-savani/distilbert-base-uncased-emotion", num_labels=6)We can call happy_tc's classify_text method to classify text.
text = "I had a lot of fun running today."
result = happy_tc.classify_text(text)
print(result)Result:
TextClassificationResult(label='joy', score=0.9929057359695435)
The output is a Dataclass with two variables: label and score. We can isolate these variables as shown below.
print(result.label)
print(result.score)Result:
joy
0.9929057359695435
Bonus: Zero-Shot Data Generation
What if you want to use a small and fast supervised model like a Naive Bayes classifier but don't have any labelled training data? You can consider using a technique I came up with last year that leverages zero-shot text classification models to label training data which is then used to fine-tune a small supervised model. You can learn more about this technique, including how to implement it with similar code from this article, within this article.
Conclusion
And that's it. To learn more about GPT-Neo, I suggest you read this article that goes into more depth on how to use it for inference and fine-tune it with Happy Transformer. To learn more about training your own supervised text classification model (like BERT) with Happy Transformer I suggest you read this article. Finally, be sure to subscribe to Vennify's YouTube channel for upcoming content on NLP.
Book a Call
We may be able to help you or your company with your next NLP project. Feel free to book a free 15 minute call with us.




